Learning the language of life with AI
El darrer article de l'Eric Topol a Science és una guia per a l'estat de situació dels models d'IA en ciències de la vida. El resum en IA és aquest:
L'article "Learning the language of life with AI" de Science tracta sobre els avenços recents en la intel·ligència artificial (IA) aplicada a les ciències de la vida, especialment en la comprensió i disseny de biomolècules. L'article destaca el ràpid progrés en aquest camp, des de models d'IA que prediuen l'estructura de proteïnes fins a sistemes multiagent que dissenyen nous anticossos.
Aquí hi ha alguns punts clau de l'article:
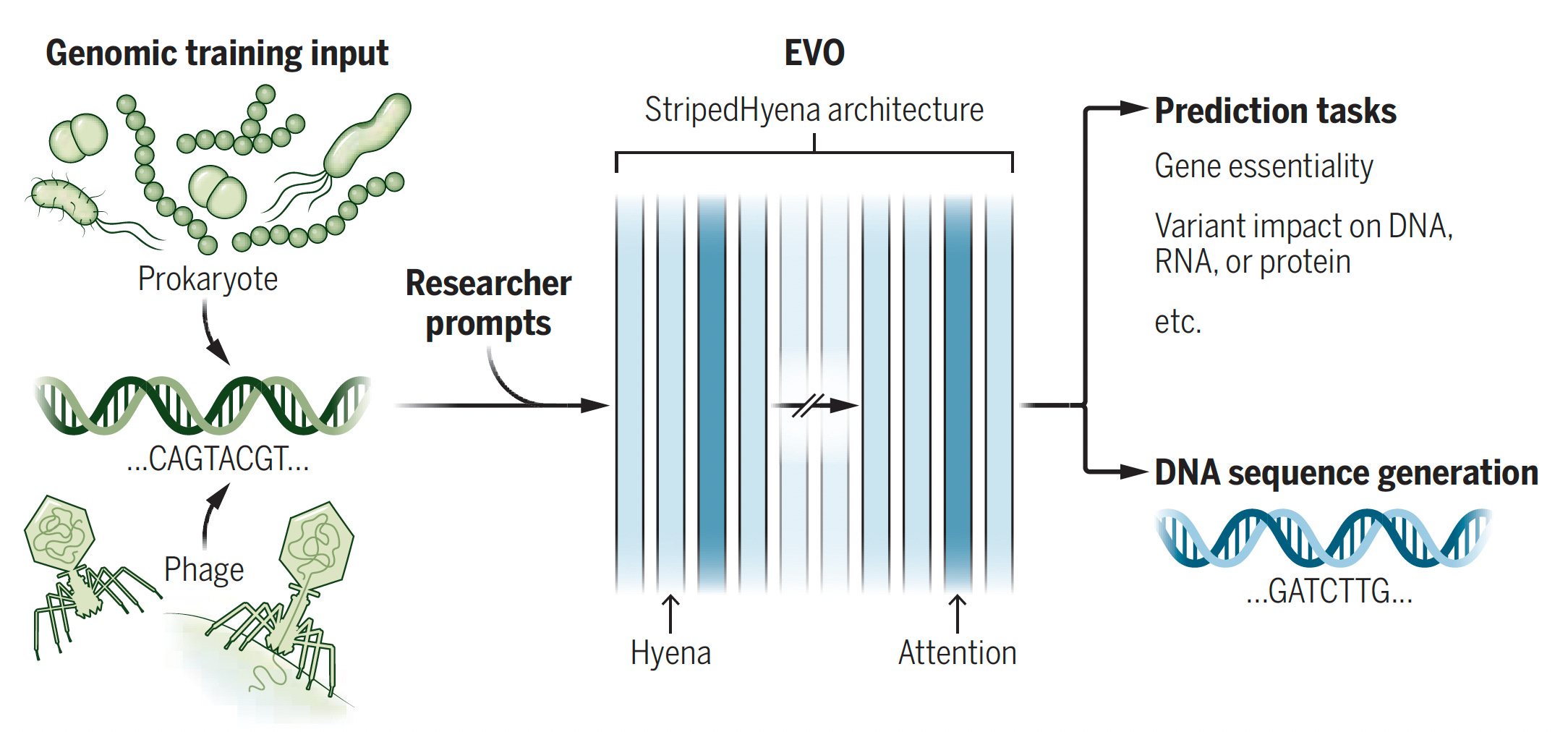
- Models de llenguatge de la vida (Large language of life models) (LLLMs): Són models d'IA que, a diferència dels models multimodals com GPT-4, processen dades de diferents capes de la biologia molecular, com ara proteïnes, ARN, ADN i lligands.
- AlphaFold 2: Aquest model va ser un precursor significatiu, ja que va resoldre el problema del plegament de proteïnes, predient estructures 3D per a més de 200 milions de proteïnes.
- Nous models: L'article descriu diversos models recentment desenvolupats, com ara:
- AlphaFold 3: Preveu l'estructura 3D de complexos de proteïnes, ADN, ARN, molècules petites i lligands.
- Boltz-1: Un model de codi obert que prediu interaccions biomoleculars amb una precisió semblant a AlphaFold 3.
- MassiveFold: Permet realitzar càlculs d'AlphaFold en paral·lel, reduint significativament el temps de computació.
- EVOLVEpro: Un model de llenguatge de proteïnes per a l'enginyeria de proteïnes guiada per IA.
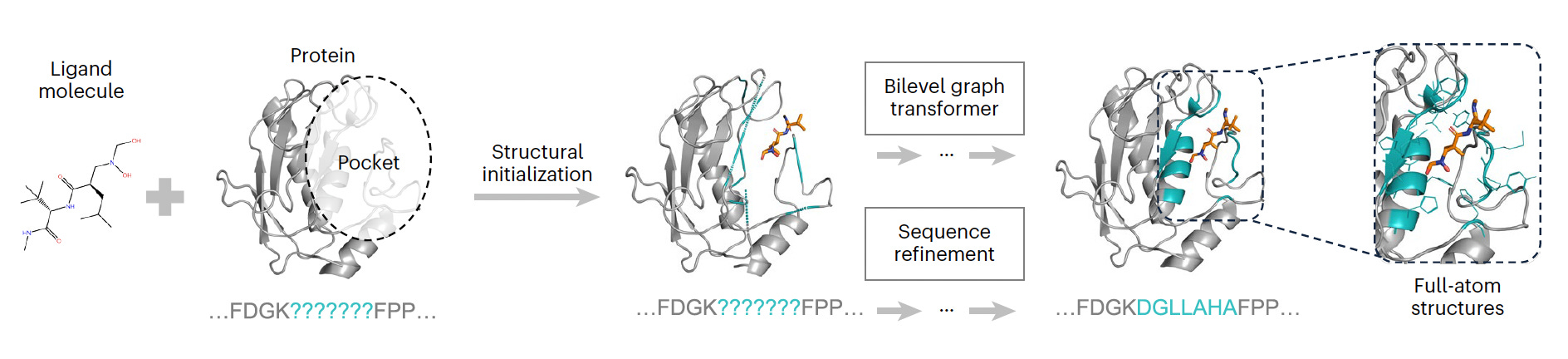
- PocketGen: Defineix l'estructura atòmica de les interaccions proteïna-lligand.
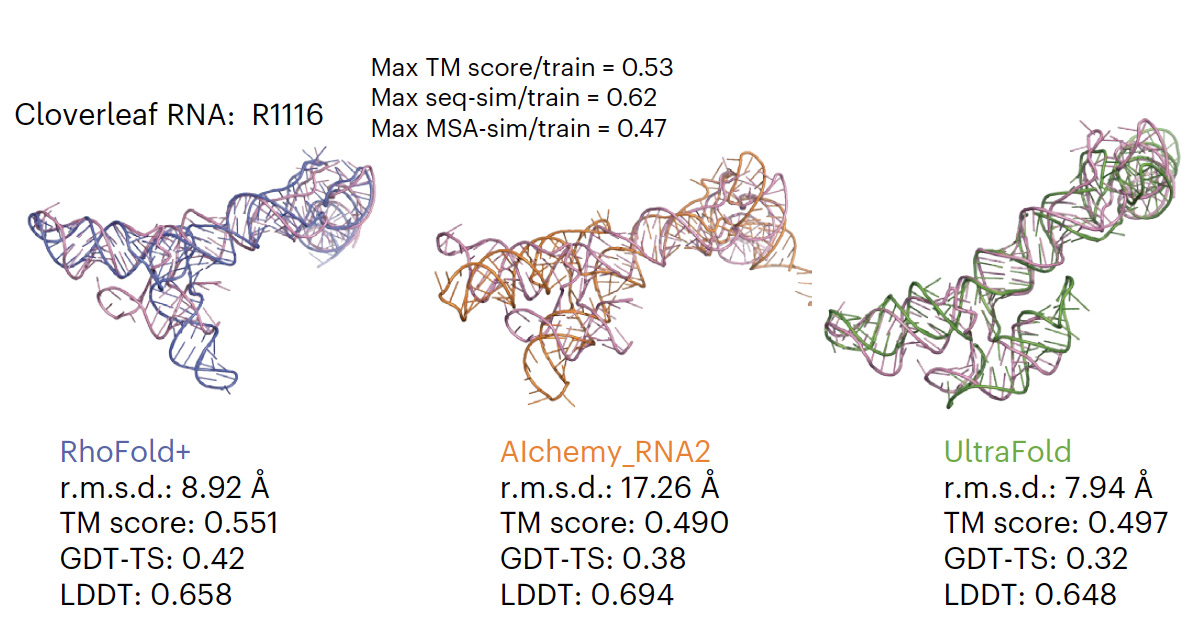
- RhoFold i RhoDesign: Per a la predicció de l'estructura 3D de l'ARN i el disseny d'aptàmers d'ARN, respectivament.
- GET (general expression transformer): Preveu quins gens es transcriuran a ARN en diversos tipus de cèl·lules humanes.
- Models de llenguatge d'ADN: Prediuen els efectes funcionals de les variacions en les regions codificants i no codificants del genoma humà.
- MethylGPT i CpGPT: Models per a anàlisis epigenètiques, com l'estimació de l'edat cronològica.
- SyntheMol: Ajuda a dissenyar i validar nous antibiòtics.
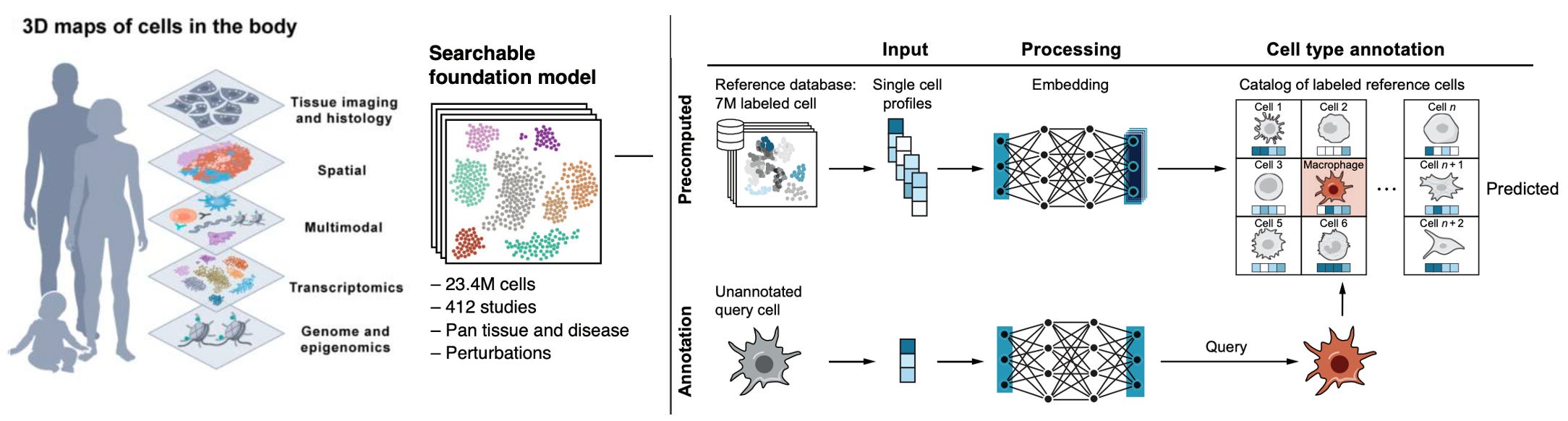
- Single-Cell Similarity (SCimilarity): Identifica un tipus de cèl·lula utilitzant l'anàlisi del veí més proper.
- Sistemes multiagent: Es menciona un sistema anomenat Virtual Lab, que utilitza múltiples agents d'IA amb diferents especialitats per dissenyar nanobodies contra el SARS-CoV-2. Aquest sistema va utilitzar tres LLLMs: AlphaFold-Multimer, Rosetta i ESM.
- Cèl·lula virtual d'IA (AIVC): L'article planteja l'aspiració de construir una AIVC per simular les accions de molècules, cèl·lules i teixits, amb l'objectiu de revolucionar la investigació biomèdica, la medicina personalitzada i altres camps.
- Digitalització de la biologia: Es compara la biologia amb l'enginyeria a causa dels avenços en IA, ja que ara es poden construir i comprendre els components de la vida mitjançant el mètode científic.
- Complexitat de la vida: Tot i el progrés, l'article adverteix que la biologia és extremadament complexa i que la comparació amb màquines o robots pot no ser suficient.
- Disponibilitat de dades: L'article destaca que hi ha una gran quantitat de dades per entrenar models d'aprenentatge automàtic, gràcies a iniciatives com el Projecte Genoma Humà, l'Atles de Cèl·lules Humanes i altres.
- L'Atles de Cèl·lules Humanes ha mapejat 62 milions de cèl·lules i té previst arribar a 1.000 milions, amb la col·laboració de 3.000 científics de 100 països.
En resum, l'article explora com els LLLMs estan transformant la biologia, permetent una comprensió més profunda i precisa dels processos biològics i la capacitat de dissenyar noves eines i solucions en medicina i biotecnologia. L'article també destaca la col·laboració entre agents d'IA i la creixent digitalització de la biologia, alhora que recorda la gran complexitat del llenguatge de la vida.